Introduction
Kafka is a damn beautiful thing, I must admit…
It makes me all googly eyed and leaves that sense of winder in me… but yeah, i’m strange like that!
I’ve been working through it for a little while now and learn some stuff. I also was met with a few challenges and wanted to share these with you.
Let’s take a quick walk through it.
What is Kafka?
The web definition:
Kafka is a distributed streaming platform that has 3 main capabilities:
- Publish and Subscribe to streams
- Store messages into streams
- Process messages before we store
That last point is what makes Kafka a beast imo. Why?
Let’s look at some pictures to understand that.
Keeping it old school
Simplified dramatically, some event driven archs may appear to look like this: https://woki.orionhealth.global/plugins/gliffy/viewer.action?wmode=opaque
While this worked for many years, we found limitations in processing performance and handling data in near real time but nothing I guess prepared our world for the
creation of the big data concept.
Storing data is always costly and usually the bulk of your software budget. To make thinks faster in this model, devs
had to either scale up the number of Db instances they had of use a multiple Db instances. This is a sore sore SORE point for member of our tech community, big pockets or small.
This entry point also made our applications the centre of attention and building our applications more complex.
Multi-threading and bad message handling was super key to ensure this was successful.
How do we manage the load?!
However it came at a cost.
- it was challenging for devs
- it made dev and testing complex
- it bloated our codebases
- it wasn’t always done right
- issues were usually only spotted once these threads ran live and encountered the real world for the first time. We’re were now in the thick of things…
This gave rise to the idea of data streaming, which rise to Kafka!
Kafka and Data streams for the win
Yes, my eyes are still googlied <- legit
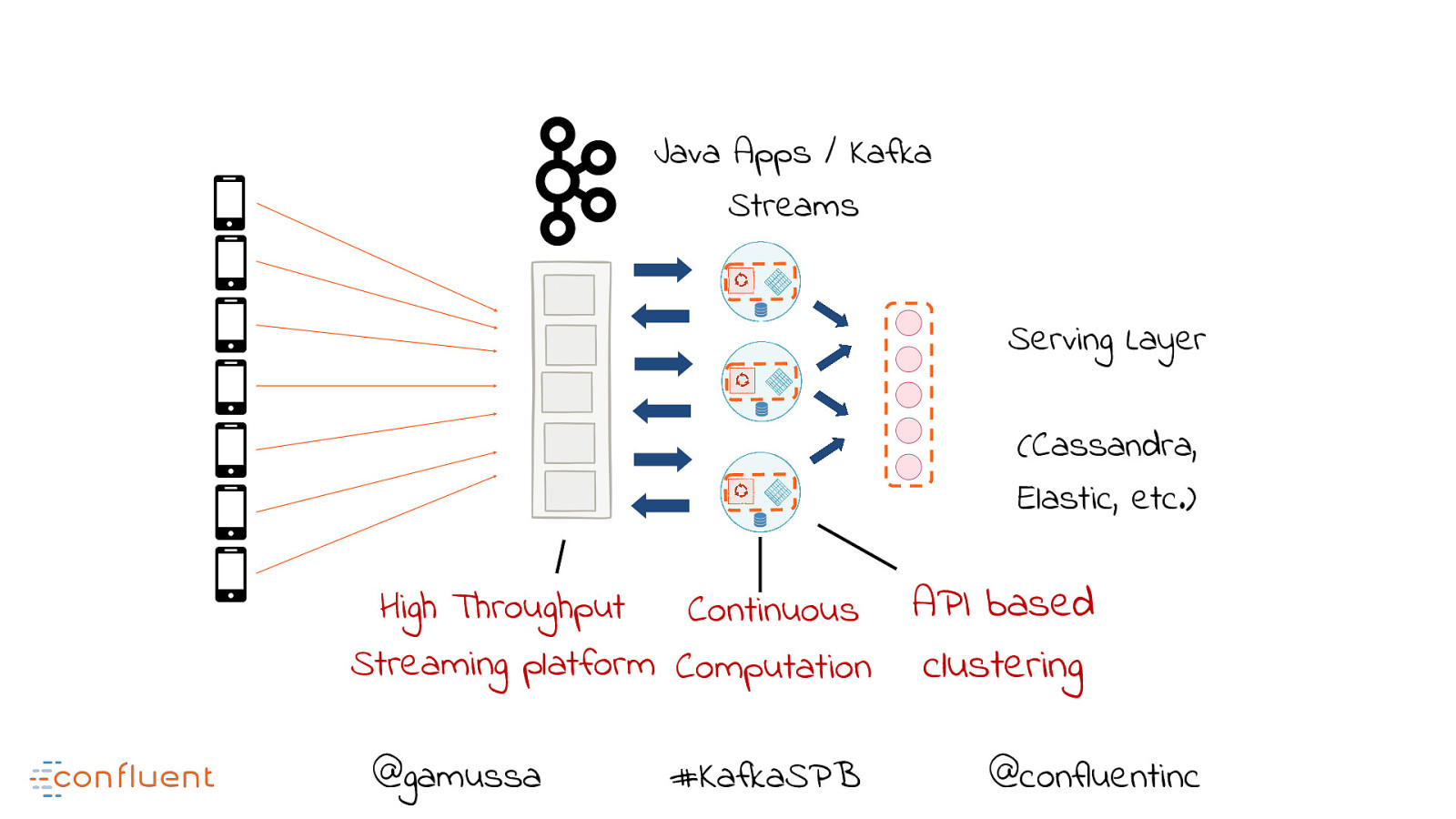
I love high performance applications. I mean, we all can build a hello world project,
but to build a highly performant, fault tolerant scalable and real time application that can process a million messages quickly
takes something hell of a special. (quick shout out to Reece and the SDP Platforms team ![]() )
)
KAFKA is purpose built for this very need. https://woki.orionhealth.global/plugins/gliffy/viewer.action?wmode=opaque

Kafka Terms and Concepts
BROKER
A Kafka broker is just a running instance of kafka.
Its the hub, the mother ship the ring leader, the conductor, the centre piece of the show the thriller in Manila…ok, too far but you get my vibe.
TOPIC
Brokers are were we create topics for consuming.
A topic is really just a layer of business logic events. for eg, if we were in the business of baking bread,
a topic of interest would be:
- “how long has the dough rested”
- “is the oven hot enough to begin”
- “how long has the bun been in the oven”
PRODUCER
A producer is one that will create or add to a topic. When an event is raised, the producer springs into action.
So in our case above, the oven would produce an event to the topics:
- “is the oven hot enough to begin”
- “how long has the bun been in the oven”
But what about the other topic?
The oven has no need to care about how long the bread has rested. It just cares if it itself is ready and if it has completed the job.
This then means the baker would be the only producer to the other topic
- “how long has the dough rested”
CONSUMER
A consumer of a topic is one that is simply subscribes to a topic and is updated when something in that topic changes.
In our bread winner example above, our baker or bakers would the consumers of all these topics…well, we hope for bread sakes!
The Kafka value
So far I’ve explained some differences and some terms, but not the value.
As seen in the Kafka image above, we are now able to do a couple of things BEFORE our application and databases are hit.
BOOM! VALUE!
We now can:
- filed multiple threads
- compute at mad speeds
- and store only when necessary
- doing all this at near real time, almost seamlessly at lower operational costs.
MORE FOR LESS -> BOOM! EVEN MORE VALUE!
The real 11 herbs and spices are in the manner in which the data is sharded, partitioned, stored, processed and read. But that a technical walk though for another day, but dang
Its like the Oprah of big data processing eh?..You feeling my love for this now?
Confluent
With all nice things in this world, people cant wait to just onboard. thankfully so!
Working with streams and stream applications, especially from a QA point of view, can be challenging, merely on the fact that
there is a very, very small set of tools for us to use to validate and gain some peek preview of data under the hood.
The team of confluent have done a job of this, check them out here:
Accessing all things streams
I have come across 3 very handy tools that do the similar thing but can be used in vary different applications and ways.
KSQL
A neat little library that lets us query a stream as if it were a database.
Pretty handy when you want to go above and beyond being a consumer of a topic.
https://www.confluent.io/product/ksql/
Kafka Control Centre
The control centre is UI designed to hook into your broker.
It will give you all the goodness of KSQL and a streams dashboard. Pretty neat.
https://docs.confluent.io/current/control-center/index.html#
Kafka Rest Proxy
https://docs.confluent.io/current/kafka-rest/index.html
Good as gold – well for me anyways!
I guess being in QA for so long has really trained my brain to push past what even i as a developer would deem normal behaviour.
i.e. just testing the application as a consumer is not enough.
The REST client is awesome and lets me integrate my integration testing platform along side my dev team and application code.
As we produce topics and messages, I get to peer into these, even before consuming it.
I can validate
- the producer
- the message
- the topic
- the partitions
- the success
- and the failures
- speed at which we are processing and latency between them. STUNNING!
Conclusion
I hope this has enlightened you a little on Kafka, streams and some tools you can use to simply your life.
We actually live in a world a streaming data…
NETFLIX
YOUTUBE
SPOTIFY
Your favourite ONLINE RETAIL store… you know those suggestions on “OTHER ITEMS YOU MIGHT LIKE”….. well…stream data…It’s all around you and I.
The introduction of tooling over Kafka is epic.
As a QA, this was imperative. I need to follow the data from start to end, leaving no bread unbaked.
It was not a simple undertaking for me.
I researched and I learnt a lot, tried loads of things and failed, leaned on people with experience to help me through and eventually found success.
All of these come neatly wrapped in docker containers. These can be run as a whole or as components. It makes working with queues a lot simpler by giving us hooks into our streams.
Dont let a subject like big data processing scare you. Get in there, get your hands dirty and fail! Fail and fail till you bake your bread.
