Its really important to define our work flow, our outputs and responsibilities within our team
When testing full stack, we need to apply QA at all levels of our engagement.

Its really important to define our work flow, our outputs and responsibilities within our team
When testing full stack, we need to apply QA at all levels of our engagement.
Templates are a great way to ensure consistency and create visibility within your teams.
We want a repeatable transparent pattern for our teams to be comfortable with and ultimately, own.
Here is an example of a template I have used:
Define your DOR
Define your ACs

Try and outlines some Use cases:

Have a section to describe high level test cases:

Define your definition of Done and Key Tasks


Cypress is great for front end mocking. Its purpose built for this with Promises in mind.Most commonly, cy.intercept is used for this.Eg.:cy.intercept(‘POST’, ‘/your-backend-api’, {}).as(‘backendAPI’);
cy.wait('@backendAPI').then(xhr => {
expect(xhr.response.statusCode).to.equal(404);
});Cypress Documentation
Network Requests | Cypress Documentation
What you’ll learn How Cypress enables you to stub out the back end with cy.intercept() What tradeoffs we make when we stub our network requests.
https://docs.cypress.io/guides/guides/network-requests
Examples for GraphQL
Cypress Documentation
Working with GraphQL | Cypress Documentation
What you’ll learn Best practices to alias multiple GraphQL queries or mutations for a group of tests. Overriding an existing intercept to modify…
https://docs.cypress.io/guides/testing-strategies/working-with-graphql
Unit Testing
For an example in .net, we can rely on something like Nunit combined wth Rest Sharp to get our GraphQL service tested.
Rest sharp is really just an option for us to make that REST call
you can use any other
Nunit, its just our assertion library, you can use any other here as well
Java based?
Well using RestTemplates and Junit would do great as basic tools.
Using Native GraphQL
Its best to try and work directly with these components.
https://www.graphql-tools.com/docs/mocking
https://graphql.org/blog/mocking-with-graphql/

‘Test infrastructure as code’ should really be part of your Test Strategy or testing game plan for the lack of one.
From experience working with docker and kubernetes, the top benefits for have been:
– easily manage the setup of Ci jobs,
– changes can be tracked and become the single source of truth,
– easily deploy test automation tooling such as selenium and pact infrastructure,
– manage Cloud costs effectively,
– setup and tear down Jenkins nodes with ease,
– easily chain jobs and share volumes if needed,
– deploying across regions, teams and environments are a breeze,
– setting up end to end development and test tooling for manual testing becomes quicker.
#automation #cloud #testing #jenkins #aws #azure #cicd #kubernetes #docker
To maximise your efficiencies as a test automation engineer, define a solid approach and plan out your test development workflow.
Below, I’ve developed a system for you to follow in building your test automation cases

I invite you to follow the same path or adapt it to meet your teams requirements.
Its good practice to follow a system and with repeatable goals defined. This will make you a stronger but also adaptable tester. Good luck!
This is an example for a /users endpoint:
Identify the API implantation and variants :
| GET /users | List all users |
| GET /users?name={username} | Get user by username |
| GET /users/{id} | Get user by ID |
| GET /users/{id}/configurations | Get all configurations for user |
| POST /users/{id}/configurations | Create a new configuration for user |
| DELETE /users/{id}/configurations/{id} | Delete configuration for user |
| PATCH /users/{id}/configuration/{id} | Update configuration for user |
| Name | Verb | How | HTTP Response Code | Assertion |
| should return a list of X resources | GET | Call endpoint | 200 | Count property should match rows.length, Count must be greater than 1 |
| should filters resources | GET | Call endpoint with filter parameters (limit, sort, start, filter) | 200 | Count property, rows.length, id of first and last resource |
| should return a specific resource | GET | Call endpoint with a resource ID | 200 | Check each property |
| should return a 404 if resource not found | GET | Call endpoint with a fake resource ID | 404 | |
| should create a resource | POST | Send full valid data | 201 | Check each property |
| should fail returning all mandatory properties | POST | Send a single non mandatory property | 400 | Count number of errors |
| should fail if … | POST | “Send data against business logic (null value, blank value, unicity, shorter than expected, bad relation …)” | 400 | Check reason/code of error |
| should update the resource | PATCH | Send full valid data (set a property id which should be ignored) | 200 | Check each property |
| should fail if … | PATCH | “Send data against business logic (null value, blank value, unicity, shorter than expected, bad relation …)” | 200 | Check reason/code of error |
| should return a 404 if resource not found | PATCH | Call endpoint with a fake resource ID and send full valid data | 404 | |
| should delete the resource | DELETE | Call endpoint with a resource ID | 204 | If hard delete, check if the resource doesn’t exist anymore in DB. If soft delete, check the resource has a deletedAt value not null |
| should delete the resource | DELETE | Call endpoint with a fake resource ID | 204 |
Where {id} is a UUID, and all GET endpoints allow optional query parameters filter, sort, skip and limit for filtering, sorting, and pagination.
| # | Test Scenario Category | Test Action Category | Test Action Description |
|---|---|---|---|
| 1 | Basic positive tests (happy paths) | ||
| Execute API call with valid required parameters | Validate status code: | 1. All requests should return 2XX HTTP status code 2. Returned status code is according to spec: – 200 OK for GET requests – 201 for POST or PUT requests creating a new resource – 200, 202, or 204 for a DELETE operation and so on | |
| Validate payload: | 1. Response is a well-formed JSON object 2. Response structure is according to data model (schema validation: field names and field types are as expected, including nested objects; field values are as expected; non-nullable fields are not null, etc.) | ||
| Validate state: | 1. For GET requests, verify there is NO STATE CHANGE in the system (idempotence) 2. For POST, DELETE, PATCH, PUT operations – Ensure action has been performed correctly in the system by: – Performing appropriate GET request and inspecting response – Refreshing the UI in the web application and verifying new state (only applicable to manual testing) | ||
| Validate headers: | Verify that HTTP headers are as expected, including content-type, connection, cache-control, expires, access-control-allow-origin, keep-alive, HSTS and other standard header fields – according to spec. Verify that information is NOT leaked via headers (e.g. X-Powered-By header is not sent to user). | ||
| Performance sanity: | Response is received in a timely manner (within reasonable expected time) – as defined in the test plan. | ||
| 2 | Positive + optional parameters | ||
| Execute API call with valid required parameters AND valid optional parameters Run same tests as in #1, this time including the endpoint’s optional parameters (e.g., filter, sort, limit, skip, etc.) | |||
| Validate status code: | As in #1 | ||
| Validate payload: | Verify response structure and content as in #1. In addition, check the following parameters: – filter: ensure the response is filtered on the specified value. – sort: specify field on which to sort, test ascending and descending options. Ensure the response is sorted according to selected field and sort direction. – skip: ensure the specified number of results from the start of the dataset is skipped – limit: ensure dataset size is bounded by specified limit. – limit + skip: Test pagination Check combinations of all optional fields (fields + sort + limit + skip) and verify expected response. | ||
| Validate state: | As in #1 | ||
| Validate headers: | As in #1 | ||
| Performance sanity: | As in #1 | ||
| 3 | Negative testing – valid input | ||
| Execute API calls with valid input that attempts illegal operations. i.e.: – Attempting to create a resource with a name that already exists (e.g., user configuration with the same name) – Attempting to delete a resource that doesn’t exist (e.g., user configuration with no such ID) – Attempting to update a resource with illegal valid data (e.g., rename a configuration to an existing name) – Attempting illegal operation (e.g., delete a user configuration without permission.) And so forth. | |||
| Validate status code: | 1. Verify that an erroneous HTTP status code is sent (NOT 2XX) 2. Verify that the HTTP status code is in accordance with error case as defined in spec | ||
| Validate payload: | 1. Verify that error response is received 2. Verify that error format is according to spec. e.g., error is a valid JSON object or a plain string (as defined in spec) 3. Verify that there is a clear, descriptive error message/description field 4. Verify error description is correct for this error case and in accordance with spec | ||
| Validate headers: | As in #1 | ||
| Performance sanity: | Ensure error is received in a timely manner (within reasonable expected time) | ||
| 4 | Negative testing – invalid input | ||
| Execute API calls with invalid input, e.g.: – Missing or invalid authorization token – Missing required parameters – Invalid value for endpoint parameters, e.g.: – Invalid UUID in path or query parameters – Payload with invalid model (violates schema) – Payload with incomplete model (missing fields or required nested entities) – Invalid values in nested entity fields – Invalid values in HTTP headers – Unsupported methods for endpoints And so on. | |||
| Validate status code: | As in #1 | ||
| Validate payload: | As in #1 | ||
| Validate headers: | As in #1 | ||
| Performance sanity: | As in #1 | ||
| 5 | Destructive testing | ||
| Intentionally attempt to fail the API to check its robustness: Malformed content in request Wrong content-type in payload Content with wrong structure Overflow parameter values. E.g.: – Attempt to create a user configuration with a title longer than 200 characters – Attempt to GET a user with invalid UUID which is 1000 characters long – Overflow payload – huge JSON in request body Boundary value testing Empty payloads Empty sub-objects in payload Illegal characters in parameters or payload Using incorrect HTTP headers (e.g. Content-Type) Small concurrency tests – concurrent API calls that write to the same resources (DELETE + PATCH, etc.) Other exploratory testing | |||
| Validate status code: | As in #3. API should fail gracefully. | ||
| Validate payload: Validate headers: | As in #3. API should fail gracefully. As in #3. API should fail gracefully. | ||
| Performance sanity: | As in #3. API should fail gracefully. |

Having automated tests are great! … but not sharing the results or centralizing them is not so great. 😦
Your automated tests have undeniable business value, don’t be shy about it. Excellence does not happen overnight. So even if your tests are in early development, share the results with your team.
So what can you do?
In conclusion:
Visibility and Reliability are really important. This makes them trust worthy, needed… valuable.
Pursue it viciously. Take small incremental steps towards implementation.

No. Not that type of ref card!
Pictured above is Mike Dean, a familiar face for those English PL football lovers.
Its been a while since we life’d per normal and I jabbered on about something. Certainly for me personally, it’s been an experience of all sorts.
Thankfully though, it has not been a difficult one and I hope the same for you.
With that, let’s get to it.
Today, it can be no surprise to you that Orion is moving into the container world at speed.
When I think containers, I think Micro-Services and when I think micro-services I think APIs.

Compared to traditional test automation, API testing is so much

When working with APIs, we have 4 main(but not limited to) sections that we would work with.
The endpoint is the actual URL under test. This is your gateway to access the information under test.
With any System under test. knowing what you’re putting in is super important as these should build the foundation of your test cases.
Most things in life come with info that isn’t really for you. This can be applied to phone calls, emails, dinner chats and even our APIs.
Meta is built into the header of your API. Sometimes this information is handy to you or set by the developers. working with headers is a need today
as most Auth services will embed a token in the header of the API.
Of course, no touching if you’re not allowed. Auth is a MUST test, must know must can do.
And last but not least, our apple… the payload.
The payload is the carrier of data, messages and usually all things requested by the consumer.
APis communicate over HTTP but do so using different methods and with any form of communication some feedback is always nice.
Apis too respond in various manner depending on circumstance.
Below is a table that represents that response code and the meaning behind it. Get familiar with these as you’ll see them quite often.
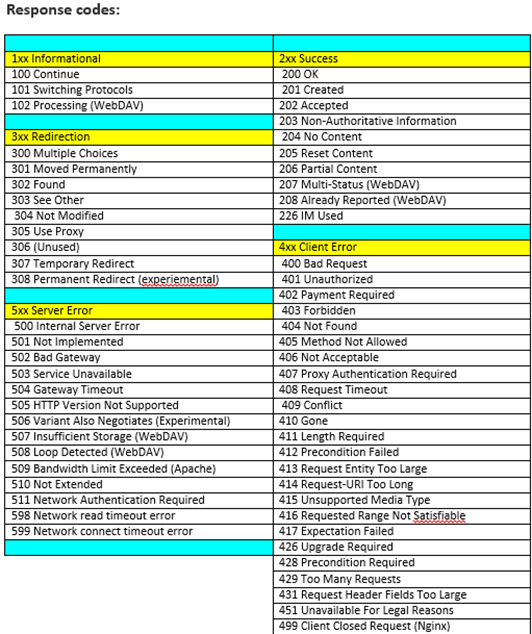
Api Testing lends itself quite easily to being structured, well documented and fast to implement.
There are heaps of tools to be used and the benefits of testing repeatedly can be seen quick.
Kafka is a damn beautiful thing, I must admit…
It makes me all googly eyed and leaves that sense of winder in me… but yeah, i’m strange like that!
I’ve been working through it for a little while now and learn some stuff. I also was met with a few challenges and wanted to share these with you.
Let’s take a quick walk through it.
The web definition:
Kafka is a distributed streaming platform that has 3 main capabilities:
That last point is what makes Kafka a beast imo. Why?
Let’s look at some pictures to understand that.
Simplified dramatically, some event driven archs may appear to look like this: https://woki.orionhealth.global/plugins/gliffy/viewer.action?wmode=opaque
While this worked for many years, we found limitations in processing performance and handling data in near real time but nothing I guess prepared our world for the
creation of the big data concept.
Storing data is always costly and usually the bulk of your software budget. To make thinks faster in this model, devs
had to either scale up the number of Db instances they had of use a multiple Db instances. This is a sore sore SORE point for member of our tech community, big pockets or small.
This entry point also made our applications the centre of attention and building our applications more complex.
Multi-threading and bad message handling was super key to ensure this was successful.
How do we manage the load?!
However it came at a cost.
This gave rise to the idea of data streaming, which rise to Kafka!
Yes, my eyes are still googlied <- legit
I love high performance applications. I mean, we all can build a hello world project,
but to build a highly performant, fault tolerant scalable and real time application that can process a million messages quickly
takes something hell of a special. (quick shout out to Reece and the SDP Platforms team ![]() )
)
KAFKA is purpose built for this very need. https://woki.orionhealth.global/plugins/gliffy/viewer.action?wmode=opaque

BROKER
A Kafka broker is just a running instance of kafka.
Its the hub, the mother ship the ring leader, the conductor, the centre piece of the show the thriller in Manila…ok, too far but you get my vibe.
TOPIC
Brokers are were we create topics for consuming.
A topic is really just a layer of business logic events. for eg, if we were in the business of baking bread,
a topic of interest would be:
PRODUCER
A producer is one that will create or add to a topic. When an event is raised, the producer springs into action.
So in our case above, the oven would produce an event to the topics:
But what about the other topic?
The oven has no need to care about how long the bread has rested. It just cares if it itself is ready and if it has completed the job.
This then means the baker would be the only producer to the other topic
CONSUMER
A consumer of a topic is one that is simply subscribes to a topic and is updated when something in that topic changes.
In our bread winner example above, our baker or bakers would the consumers of all these topics…well, we hope for bread sakes!
So far I’ve explained some differences and some terms, but not the value.
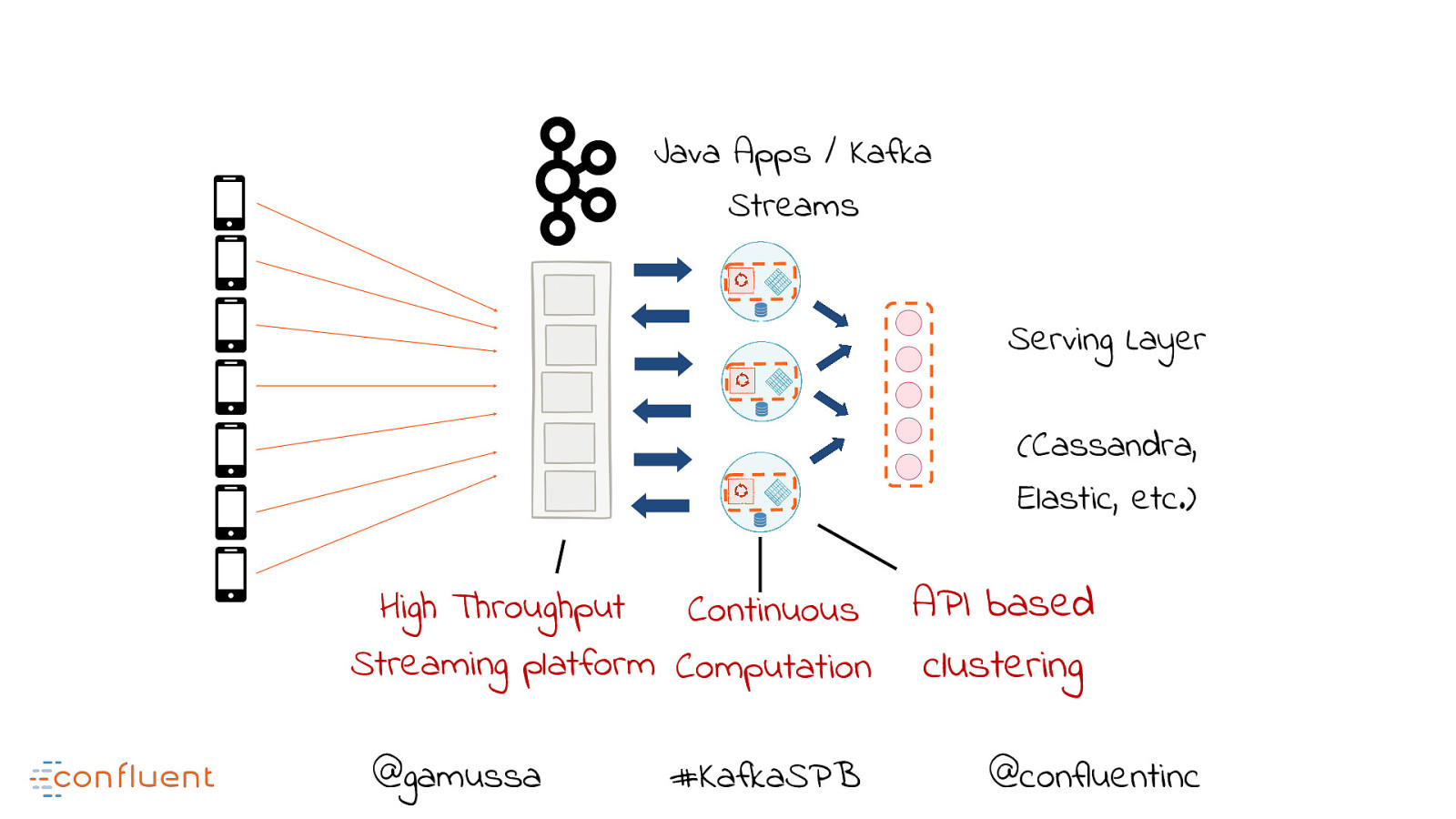
As seen in the Kafka image above, we are now able to do a couple of things BEFORE our application and databases are hit.
BOOM! VALUE!
We now can:
MORE FOR LESS -> BOOM! EVEN MORE VALUE!
The real 11 herbs and spices are in the manner in which the data is sharded, partitioned, stored, processed and read. But that a technical walk though for another day, but dang
Its like the Oprah of big data processing eh?..You feeling my love for this now?
With all nice things in this world, people cant wait to just onboard. thankfully so!
Working with streams and stream applications, especially from a QA point of view, can be challenging, merely on the fact that
there is a very, very small set of tools for us to use to validate and gain some peek preview of data under the hood.
The team of confluent have done a job of this, check them out here:
I have come across 3 very handy tools that do the similar thing but can be used in vary different applications and ways.
A neat little library that lets us query a stream as if it were a database.
Pretty handy when you want to go above and beyond being a consumer of a topic.
https://www.confluent.io/product/ksql/
The control centre is UI designed to hook into your broker.
It will give you all the goodness of KSQL and a streams dashboard. Pretty neat.
https://docs.confluent.io/current/control-center/index.html#
https://docs.confluent.io/current/kafka-rest/index.html
Good as gold – well for me anyways!
I guess being in QA for so long has really trained my brain to push past what even i as a developer would deem normal behaviour.
i.e. just testing the application as a consumer is not enough.
The REST client is awesome and lets me integrate my integration testing platform along side my dev team and application code.
As we produce topics and messages, I get to peer into these, even before consuming it.
I can validate
I hope this has enlightened you a little on Kafka, streams and some tools you can use to simply your life.
We actually live in a world a streaming data…
NETFLIX
YOUTUBE
SPOTIFY
Your favourite ONLINE RETAIL store… you know those suggestions on “OTHER ITEMS YOU MIGHT LIKE”….. well…stream data…It’s all around you and I.
The introduction of tooling over Kafka is epic.
As a QA, this was imperative. I need to follow the data from start to end, leaving no bread unbaked.
It was not a simple undertaking for me.
I researched and I learnt a lot, tried loads of things and failed, leaned on people with experience to help me through and eventually found success.
All of these come neatly wrapped in docker containers. These can be run as a whole or as components. It makes working with queues a lot simpler by giving us hooks into our streams.
Dont let a subject like big data processing scare you. Get in there, get your hands dirty and fail! Fail and fail till you bake your bread.
Over the past then years that I’ve been in the industry, I have been fortunate enough to bear witness to the beautiful way software delivery methods have evolved.
From long lasting design of monoliths to quick and in some cases, daily deploys of micro-services, we have come a long long way but our journey is not done.
Today, we’re moving faster than ever into cloud, serverless, containers and SaaS.
The key to this revolution was communication. There is indeed, strength in numbers.
Knowing that we were not struggling alone. That our issues were not unique and that others solved them was comforting, motivating and enlightened us.
We all became students and masters at the same time. We read, research, learn insatiably. GIVE ME ALL THE KNOWLEDGES!
Learning how to do things better,
Learning how others found success in similar situations! YAS!
We’re amped! We’re pumped, we try it out and its going to be amazing…and it fails!
Its hard…its not working…its taking longer than expected.
wait.. what?!
Variables. Life just happened. It sucks, but its a lesson that was always yours…waiting for just you.
As a lead, take careful consideration of your projects strength and weaknesses.
These Risks will surely impact your delivery.

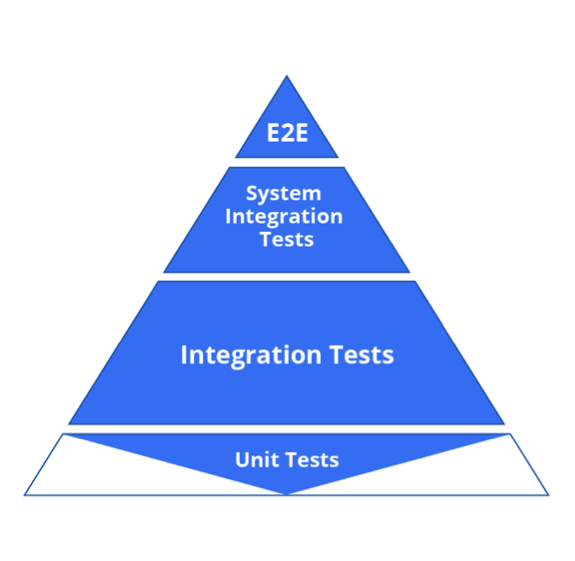
With the introduction of micro-services, we have seen testing get pushed left.
Like into the bush and we forget about it? Erhm…NO.
By pushing testing left, we attempt to push the top tiers of the pyramid down.
So an example here would be, refining our system tests to pose as integration tests instead.
The goal of this concept has always been the same, faster feedback.
TIP: Dont get bogged down by the concept but rather focus on the goal, shift can happen in both directions.
Build a vision for delivery with your team.
Understand each move your people and software makes and draw a picture.
Create flow diagrams and maintain this as you and the team grows…making it your own and not an internet copy and paste.
Most of the time, everything you read will be wrong for you. OMG…
I just mean that when we read something, most of the time we dont have the full picture. The new start in your team or the exit of an old soul will dramatically change how you deliver. Shift and adapt with it.
TIP: Dont forget to address your delivery process often!
Below is an example and a good head start for you to build and share your flow. Make it your own!

As you forge forward in your ambitions to delivery high quality software sooner, build a plan that is lean but high value to your team.
